
ElasticSearch相似度打分算法
1-TF
TF(Term Frequency)——词语频率,也称词频
-
算法
词条在文档出现的频率——
Σ关键词出现次数/该文档的总词数
(这里的Σ就是算出所有词频,然后相加) -
eg
用户搜索——【A,B】
ES索引库里的所有文档
[A,D,G] [C,F,W],[K,I,O]A在第一条文档出现了1次,总词数为3则——1/3===》0.333分
B在第一条一次都没出现====》0分
最终检索出来的0.333+0=0.333分检索出第一条文档,至此我们解决了词语出现次数排列检索结果
但是,如果一条文档里,有很多我们不想要检索的词条呢?例如,苹果出现了1次,而我不小心连续输入了20次啊,那么该分数会偏高,甚至高于其他有关键字的,例如搜出只有一条是"苹果啊啊...x20",其他索引全是"啊啊啊x20",最终覆盖掉我们需要的信息,此时引出了TF-IDF ——解决了词条权重问题
2-TF-IDF
就是在TF的基础上,乘一个IDF
IDF(Inverse Document Frequency)
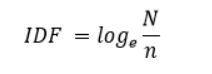
N:总文档数
n:出现次数
为了防止一次都没出现n为0的情况,我们给分母+1(平滑操作)
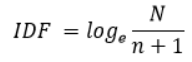
- eg
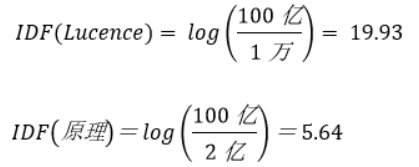
此时我们更想要看到的Lucence权重更大
- 最终式子

3-BM25
BM(Best Matching)
第一次修改
- 在原先的TF-IDF将TF做了修改
在传统的TF值理论可以无限大增加一个常量k做出一个限制
两者公式
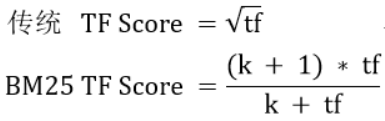
-
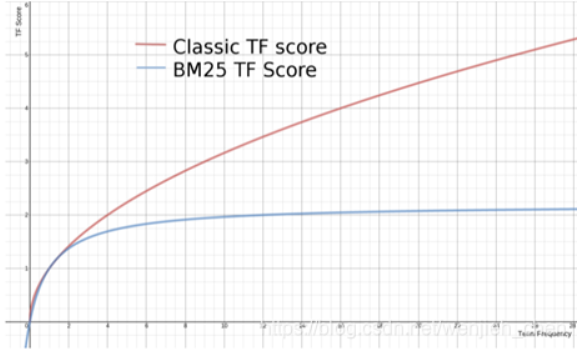
传统的tf(出现次数)增加时TF Score增加幅度很大,甚至无限
-
BM25的TF Score会被限制在0~k+1间,最终趋于水平,k=1.2,使用者可修改
第二次修改
-
引入了平均文档长度概念,探究单个文档长度和平均所有文档长度间比值对TF Score的影响

-
-
b:常量。决定L对评分的的影响
-
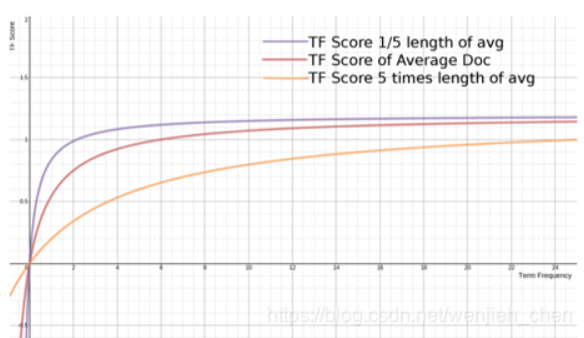
不同L,对词频TF Score影响的走势
-
文档越短,斜率(区域上限的速度)越大,反之慢
eg:- 词少的文档,匹配词少,快速确定相关性
词少,文档长度小,L小,L在分母,分母小,整体大 - 打个比方。大篇幅内容,1本书内容,需匹配大量内容才知道重点
- 词少的文档,匹配词少,快速确定相关性
-
这里的参数b就是决定了L对评分的影响力度
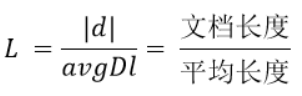

最终公式
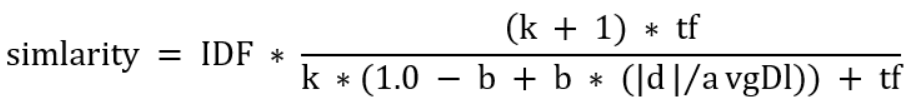
优势
- 可调节参数k,b——灵活
好厉害,没学过也没看懂
我那个时候学着玩的哈哈哈,前置知识差的有点多😂
666
66666