分布式存储(docker里Redis集群配置)-理论
前言(引入)
Redis,内存中的数据存储结构系统,采用键值对存储模型
优点
- 数据缓存快(相较于传统的关系型数据库mysql,存放在固态硬盘或者磁盘,其内存读写速度快)
存在的问题
- 内存存储是一种易失性的存储介质,断电导致数据丢失
解决方案
-
定期写入磁盘(自动保存)
有两种持久化方案- RDB持久化 (redis database)
在指定的时间内,根据要求的数据(键)变化量进行保存(快照)
例如:save 900 1 ——在900秒内,至少一个键发生变化,保存1次
自动保存的时候服务器会阻塞,使用BGSAVE命令(创建子进程进行快照,快照生成完后子进程退出,客户端通过返回值确定快照生成状态,返回Background saving start表示生成已开始)
注意:BGSAVE虽然是在后台执行,可在生成过程仍然会占用系统资源,如CPU和内存,数据非常大的时候,仍然会对服务器的性能产生影响
可以用LASTSAVE命令获取最后一次成功执行RDB快照的时间戳
每次快照形成新的文件,不会覆盖之前文件
- AOF持久化(Append Only File)
以追加的方式将Redis的写操作记录到文件,通过记录操作日志,在服务器重启时重新执行操作来恢复还原数据,修改Redis.conf配置文件。找到并修改以下配置项
appendonly yes # 启用AOF持久化 appendfsync everysec # 每秒钟将AOF缓冲区写入磁盘- 二者区别:
AOF的写操作详细信息比RDB快照大小存储占用更大
AOF提供更高的数据安全性和灾难恢复能力,而RDB更适合快速备份和恢复操作
可以根据需求选择持久化机制,也可以一起选,根据磁盘空间情况和对数据存储的要求而定
好了BB这么多,接下来进入正题
Q:假设有1-2亿条数据需要用Redis缓存,如何设计这个存储案例?
A:用单台单机100%是不可能的,所以使用分布式存储(多台Redis,集群)
- 哈希取余
- 一致性哈希取余
- 哈希槽算法
哈希取余算法
首先确定有n台Redis(哈希表的大小),和一些数据,每条数据都有特定的键
对于每个键,我们通过哈希函数将其映射到不同的整数,通过不同的整数进行对n取余运算,结果为该数据需放入哪台redis(0为第一台)从而实现对数据均衡负载
Q/A
Q:如何将键转化为哈希值?
A:通过哈希函数实现
- 散列函数(Hash Function):
将输入值映射到固定长度的二进制字符串,称为哈希码或摘要(digest)常见的散列函数为MD5,SHA-1 SHA-256 - 自定义哈希函数:
DIY函数,利用输入值的特殊属性进行转换,如字符串的ASCII阿斯玛,数值的位运算,0000 0001,等。例如hello, (104++101+108*2+111=532)
通过ASCII码相加得到最终哈希值位532
特点/存在的意义
- 一致性/完整性:相同的输入值产生相同的输出
eg:密码的存储和验证,密码通常不会以明文保存在数据库,而是通过哈希函数,MD5加密转化为哈希值(唯一不变)当用户登录时,输入的密码转换为已存在的哈希值,如果符合,则登录成功
文件校验,数字签名,哈希值可以用于验证数据的完整性,确保数据在传输或存储过程中没有被篡改或损坏。发送方可以通过计算数据的哈希值,并将其与接收方计算得到的哈希值进行比对,若两者一致,则可以确认数据的完整性。 - 均匀性:好的散列函数能够尽可能将输入值的不同均匀反映在输出,即使输入有一点不一样或变化,输出值都有显著的变化,减少冲突
eg:数据唯一标识,区分,在数据存储和索引,查找等场景发挥作用 - 高效性:好的散列函数的计算是高效的,能在合理的时间处理大量数据
- 不可逆性:
散列函数是单向的,只能从值转换为哈希值,不能反过来,保护了输入值的机密性,在密码学中很重要
缺点
当数据存储到一半的时候,有一台突然宕机了,那么n发生变化,所有哈希值重新分配到redis,会出现数据倾斜,等其他问题,这时候就引出了另一种第二种分布式存储,一致性哈希取余
一致性哈希取余算法
区别之前的哈希取余的是,节点和键为映射到一个圆环上的某一个位置,键值对经过同样的hash函数得到的值落在圆环上,顺时针遇到的第一个节点为为存储的位置
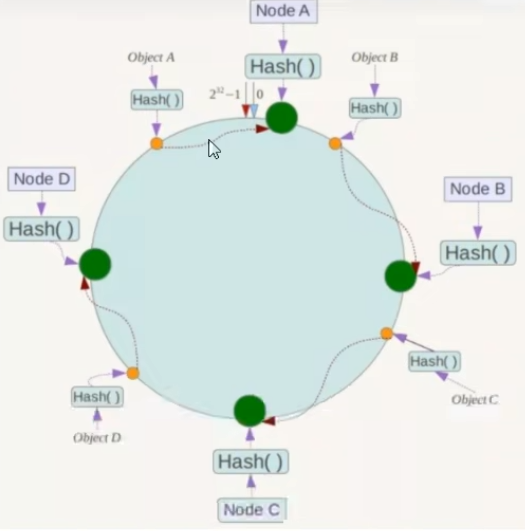
如果C宕机了,落在BC区间的数据就会跑到D,由原来的四个区域变为三个区域,D的数据量承载量将会增多,而其他的两台机子存储量不变,如果采用哈希取余,看成一条直线上的四台机子,如果一台挂掉了,除数n发生变化,所有数据都将重新从redis拿出来进行洗牌均衡负载,而一致性避免了该问题
优点
- 容错性,节点的倒闭不会重新洗牌,而是顺时针到最近的一台
- 扩展性,节点的增加不会重新洗牌,而是原来落点的键,由一台,变到插入的一台新的,
缺点
节点不是均匀分布,导致数据存储也达不到均匀分布
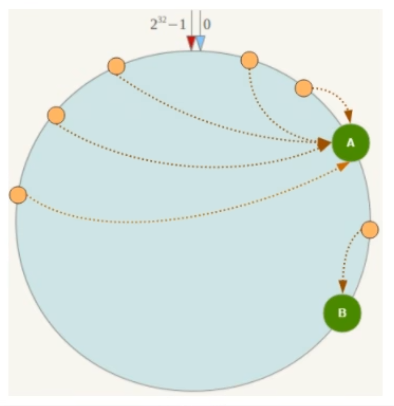
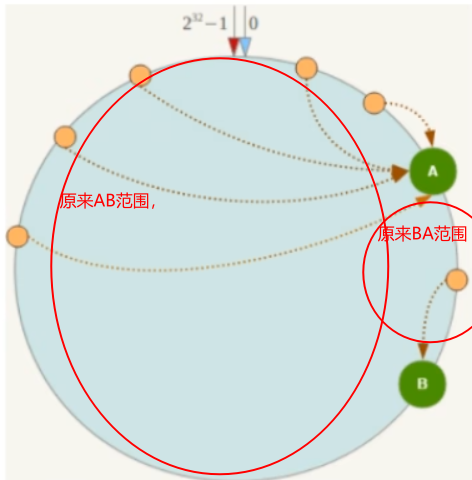
容易产生数据倾斜,由于是顺时针走的,如果A,B间隔太近。落在AB间的数据概率不高,所以B数据存储量少。而BA这一段的范围大,A存储数据量大,数据倾斜
Tip:每个节点存放的数据量大小可以想象成该节点到上一个节点的范围,如果上一个节点崩了。产生雪崩效应,则当前节点会存储大量数据,后续的数据顺时针存储机制也会使该节点的承载量大于其他节点
哈希槽算法
在一致性哈希算法的数据倾斜进行了改良,数据和节点之间多了一层哈希槽
- 一个集群有16384个槽(2^14^)
为什么不是2^16^(65536)个?- 如果有65536个槽位,发送心跳信息头达8k,心跳包过于庞大,而redis节点血药发送一定数量的ping消息作为心跳包,槽位65536,ping消息头过大,浪费带宽
- redis节点不可能超过1000个,而16384槽位足以覆盖1000个节点,没必要扩展到65536
- 槽位越小,节点少,压缩比高,容易传输
redis主节点配置信息中负责哈希槽是通过 一张bitmap形式保存,传输过程对其进行压缩,
slot槽/N节点=压缩率,N大压缩率小,N小压缩率大
假设现在有三个节点N=3,将16384个槽位分配给所有节点,集群记录节点和槽的对应关系,也就是将16384个槽均分给三个节点。每个节点记录拥有哪些槽,将数据key求哈希值,再对16384取余,余数几就落入对应的槽里,slot=CRC16(key)%16384,以槽的单位移动数据,而槽的数目范围是相对的,这样就解决了数据倾斜问题。
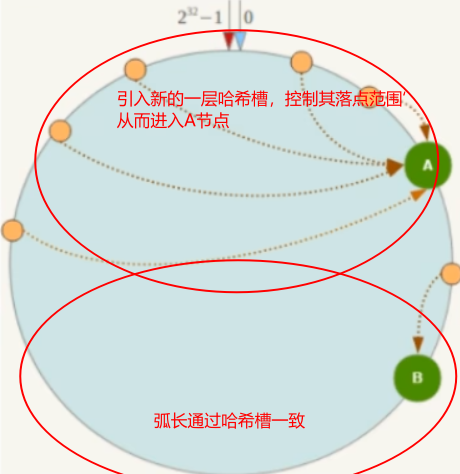
简单点来说,就是由原来的落到节点,变为落到槽,再落到节点。而原来落到节点的范围是不一致的,这里引用的槽范围一致,解决了数据倾斜问题,可以想象成一致性哈希如果节点过少,且节点在环上的距离过近,AB段的弧长太大,数据落在AB段后走顺时针进入节点的概率大,数据倾斜,这里引入的哈希槽就是将AB段和BA段的弧长用哈希槽的方法均等,这样数据落在AB范围的槽进入节点1和落在BA范围的槽进入节点2的概率是一样的,从而达到数据均衡。如果加入或删除了哪个节点,只需要将槽对新的节点数量进行重新划分即可,以下是启发图
实战
关闭防火墙,启动docker服务
systemctl stop firewalld
systemctl start docker新建6个docker容器实例
# 启动第1台节点
# --net host 使用宿主机的IP和端口,默认
# --cluster-enabled yes 开启redis集群
# --appendonly yes 开启redis持久化
# --port 6381 配置redis端口号
docker run -d --name redis-node-1 --net host --privileged=true -v /app/redis-cluster/share/redis-node-1:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6381
# 启动第2台节点
docker run -d --name redis-node-2 --net host --privileged=true -v /app/redis-cluster/share/redis-node-2:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6382
# 启动第3台节点
docker run -d --name redis-node-3 --net host --privileged=true -v /app/redis-cluster/share/redis-node-3:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6383
# 启动第4台节点
docker run -d --name redis-node-4 --net host --privileged=true -v /app/redis-cluster/share/redis-node-4:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6384
# 启动第5台节点
docker run -d --name redis-node-5 --net host --privileged=true -v /app/redis-cluster/share/redis-node-5:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6385
# 启动第6台节点
docker run -d --name redis-node-6 --net host --privileged=true -v /app/redis-cluster/share/redis-node-6:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6386进入容器,构建主从关系
进入节点1(或任意一个)
docker exec -it redis-node-1 /bin/bash构建主从关系
# 宿主机IP:端口
# --cluster-replicas 1集群关联1:1.1主1从
#此处的xxx为你宿主机的ip
redis-cli --cluster create 192.168.xxx.xxx:6381 192.168.xxx.xxx:6382 192.168.152.135:6383 192.168.xxx.xxx:6384 192.168.152.135:6385 192.168.xxx.xxx:6386 --cluster-replicas 1输入yes

槽分配成功

查看集群状态
进入容器节点1
docker exec -it redis-node-1 /bin/bash使用cli命令行连接6381节点
redis-cli -p 6381查看集群状态
cluster info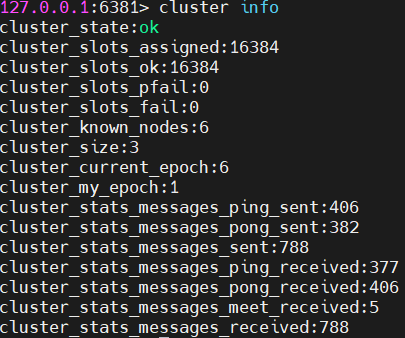
分配的槽数量cluster_slots_assgined为16384,集群节点数量 cluster_known_nodes为6
查看集群节点信息
cluster nodes
我们可以发现,slave从6386尾号6f414挂在了6381下,
其挂载是打乱无规律的
